
今天,芯片初创公司Cerebras Systems推出了全新的Wafer Scale Engine 3,并将其现有的最快 AI 芯片世界纪录加倍。据介绍,在相同的功耗和相同的价格下,WSE – 3的性能是之前的记录保持者Cerebras WSE-2的两倍。
基于 5nm 的4万亿晶体管WSE-3专为训练业界最大的 AI 模型而构建,为Cerebras CS-3 AI 超级计算机提供动力,通过900,000 个 AI优化计算核心提供 125 petaflops 的峰值 AI性能。

一颗惊人的芯片,约等于62颗H100
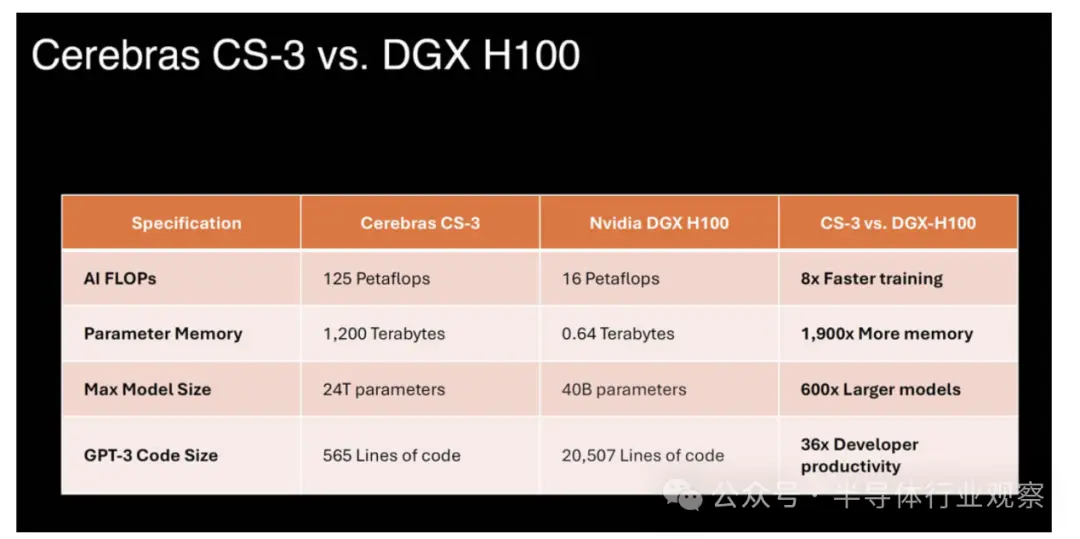
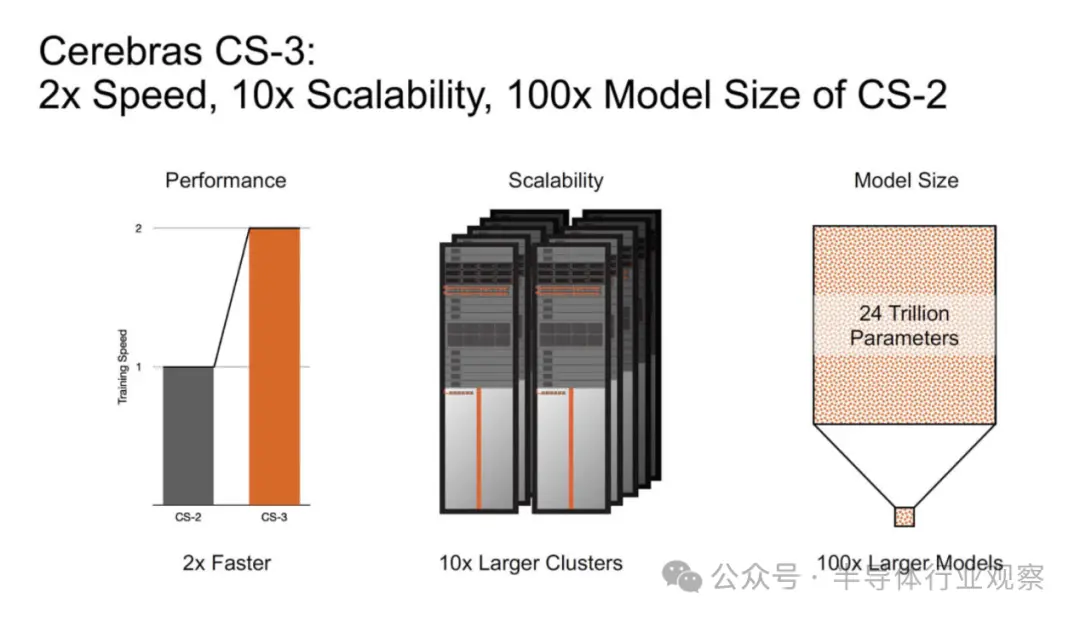
Cerebras Systems表示,这款新器件使用台积电的5nm工艺打造,包含 4 万亿个晶体管;90万个AI核心;44GB 片上 SRAM;;外部存储器为1.5TB、12TB或1.2PB;峰值性能为 125 FP16 PetaFLOPS。Ceberas 的 WSE-3 将用于训练一些业界最大的人工智能模型,能训练多达 24 万亿个参数的 AI 模型;其打造的集群规模高达 2048 个 CS-3 系统。

值得一提的是,当 Cerebras 提到内存时,他们谈论的更多是 SRAM,而不是片外 HBM3E 或 DDR5。内存与核心一起分布,目的是使数据和计算尽可能接近。
为了展示这颗新芯片的规模,Cerebras 还将其与英伟达的H100进行了对比。

除了将这款巨型芯片推向市场之外,Cerebras 取得成功的原因之一是它所做的事情与 NVIDIA 不同。NVIDIA、AMD、英特尔等公司采用大型台积电晶圆并将其切成更小的部分来制造芯片,而 Cerebras 将晶圆保留在一起。在当今的集群中,可能有数以万计的 GPU 或 AI 加速器来处理一个问题,将芯片数量减少 50 倍以上可以降低互连和网络成本以及功耗。在具有 Infiniband、以太网、PCIe 和 NVLink 交换机的 NVIDIA GPU 集群中,大量的电力和成本花费在重新链接芯片上。Cerebras 通过将整个芯片保持在一起来解决这个问题。凭借 WSE-3,Cerebras 可以继续生产世界上最大的单芯片。它呈正方形,边长为 21.5 厘米,几乎使用整个 300 毫米硅片来制造一个芯片。
你可以在WSE芯片的相继推出中看到摩尔定律的作用。第一个于 2019 年首次亮相,采用台积电的 16 纳米技术制造。对于 2021 年推出的 WSE-2,Cerebras 转而采用台积电的 7 纳米工艺。WSE-3 采用这家代工巨头的 5 纳米技术制造。
自第一个巨型芯片问世以来,晶体管的数量增加了两倍多。与此同时,它们的用途也发生了变化。例如,芯片上的人工智能核心数量已显着趋于平稳,内存量和内部带宽也是如此。尽管如此,每秒浮点运算(flops)方面的性能改进已经超过了所有其他指标。
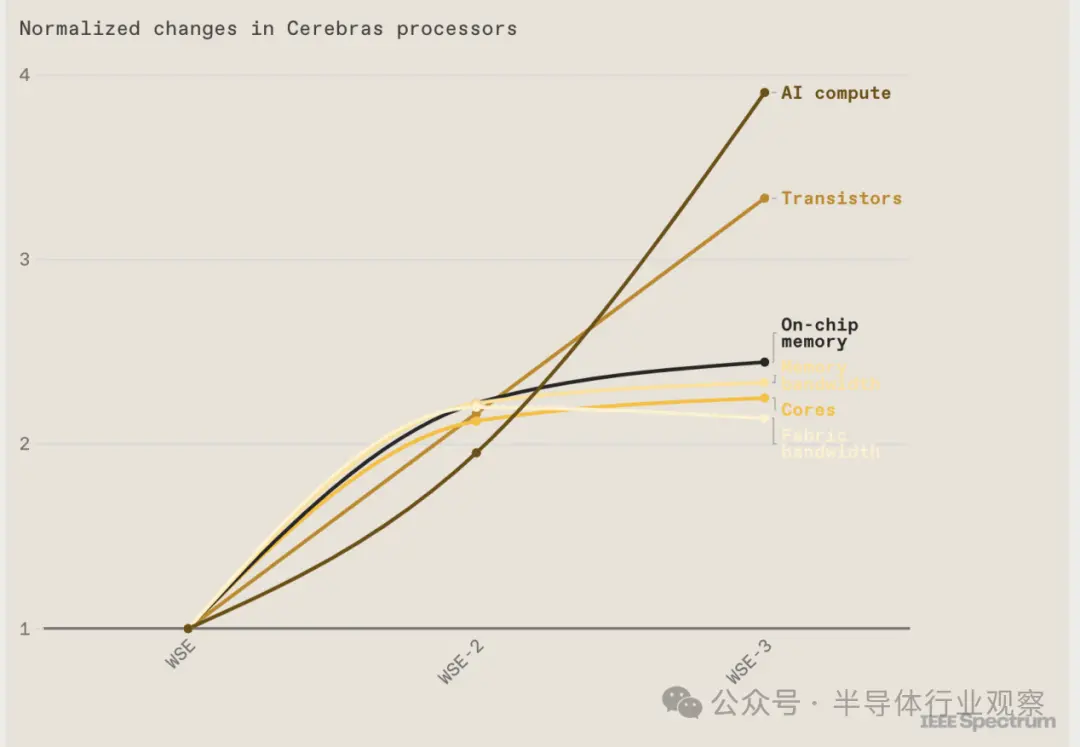
需要注意的一点是,Cerebras 使用片上内存,而不是 NVIDIA 的封装内存,因此我们不会以 H100 上的 80GB HBM3 为例。

最新的 Cerebras 软件框架为PyTorch 2.0 和最新的 AI 模型和技术(如多模态模型、视觉转换器、专家混合和扩散)提供原生支持。Cerebras 仍然是唯一为动态和非结构化稀疏性提供本机硬件加速的平台,将训练速度提高了8 倍。
您可能已经看到 Cerebras 表示其平台比 NVIDIA 的平台更易于使用。造成这种情况的一个重要原因是 Cerebras 存储权重和激活的方式,并且它不必扩展到系统中的多个 GPU,然后扩展到集群中的多个 GPU 服务器。
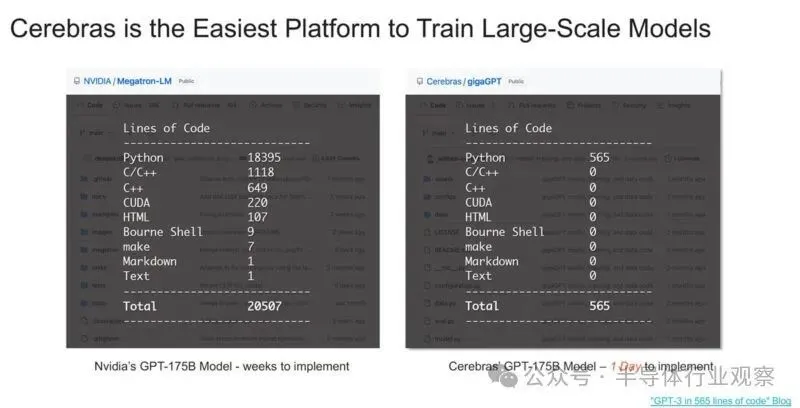
除了代码更改很容易之外,Cerebras 表示它的训练速度比 Meta GPU 集群更快。当然,目前这似乎是理论上的 Cerebras CS-3 集群,因为我们没有听说有任何 2048 个 CS-3 集群启动并运行,而 Meta 已经有了 AI GPU 集群。

总体而言,这里发生了很多事情,但我们知道的一件事是,如今越来越多的人使用基于 NVIDIA 的集群。
Cerebras Systems进一步指出,由于每个组件都针对 AI 工作进行了优化,CS-3 比任何其他系统都能以更小的空间和更低的功耗提供更高的计算性能。虽然 GPU 功耗逐代翻倍,但 CS-3 的性能翻倍,功耗却保持不变。CS-3具有卓越的易用性,与适用于大模型的GPU 相比, CS-3需要的代码减少 97% ,并且能够在纯数据并行模式下训练从 1B 到24T 参数的模型。GPT -3大小的模型的标准实现在 Cerebras 上只需要 565 行代码——这同样也是行业记录。
一个庞大的系统,冷却超乎想象
Cerebras CS-3 是第三代 Wafer Scale 系统。其顶部具有 MTP/MPO 光纤连接,以及用于冷却的电源、风扇和冗余泵。
Cerebras Systems在新闻稿中指出,如上所述,CS-3拥有高达 1.2 PB的巨大内存系统,旨在训练比 GPT-4 和 Gemini 大 10 倍的下一代前沿模型。24 万亿参数模型可以存储在单个逻辑内存空间中,无需分区或重构,从而极大地简化了训练工作流程并提高了开发人员的工作效率。在 CS-3 上训练一万亿参数模型就像在 GPU 上训练十亿参数模型一样简单。
CS-3专为满足企业和超大规模需求而打造。紧凑的四系统配置可以在一天内微调 70B 模型,而使用 2048 个系统进行全面调整,Llama 70B 可以在一天内从头开始训练——这对于生成 AI 来说是前所未有的壮举。

Cerebras 需要为巨型芯片提供电力、数据和冷却,同时还要管理相对较大区域的热膨胀等问题。这是该公司的另一项重大工程胜利。芯片内部采用液体冷却,热量可以通过风扇或设施水排出。
该系统及其新芯片在相同的功耗和价格下实现了大约 2 倍的性能飞跃。从第一代的 16 纳米到如今的 5 纳米,Cerebras 从每个工艺步骤中都获得了巨大的优势。
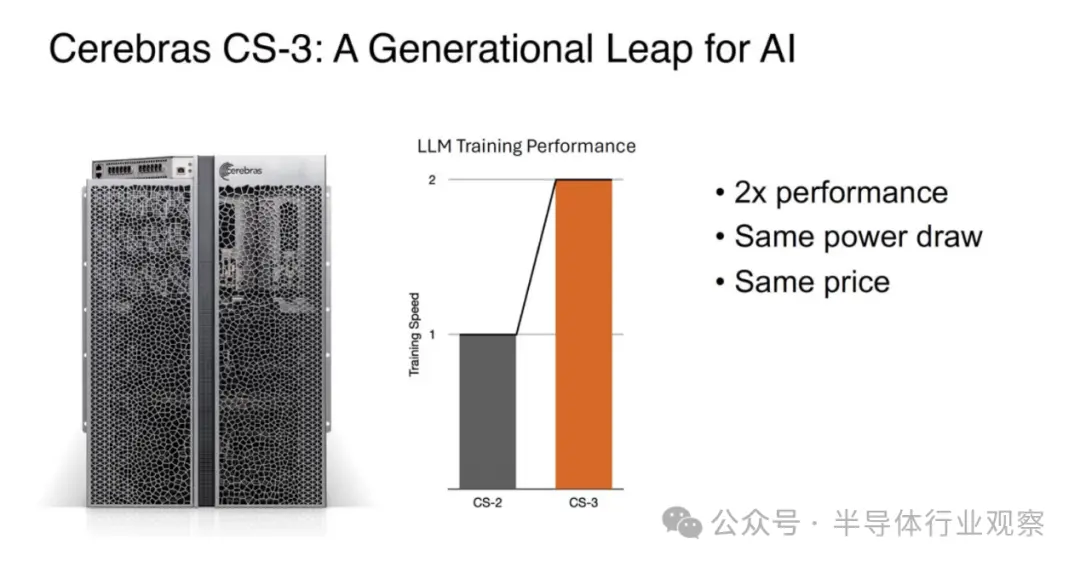
与具有八个 NVIDIA H100 GPU 以及内部 NVSwitch 和 PCIe 交换机的 NVIDIA DGX H100 系统相比,它只是一个更大的构建块。
这是带有 Supermicro 1U 服务器的 CS-3。

这是另一个使用 Supermciro 1U 服务器拍摄的 Cerebras 集群。Cerebras 通常使用 AMD EPYC 来获得更高的核心数量,这可能是因为 Cerebras 团队的很多成员来自被 AMD 收购的 SeaMicro。

我们在这次迭代中注意到的一点是,Cerebras 也有 HPE 服务器的解决方案。这有点奇怪,因为一般来说,Supermicro BigTwin 比 HPE 的 2U 4 节点产品领先一步。

看待 Cerebras CS-2/CS-3 的一种方式是,它们是巨大的计算机器,但许多数据预处理、集群级任务等都发生在传统的 x86 计算上,以提供优化的人工智能芯片。

由于这是一个液冷数据中心,因此风冷 HPE 服务器配备了来自 Legrand 子品牌 ColdLogik 的后门热交换器设置。
这是 Cerebras 如何利用液冷设施的一个很好的例子,但它不必为每个服务器节点配备冷板。
这一代的一大特点是更大的集群,多达 2048 个 CS-3,可实现高达 256 exaFLOPs 的 AI 计算。
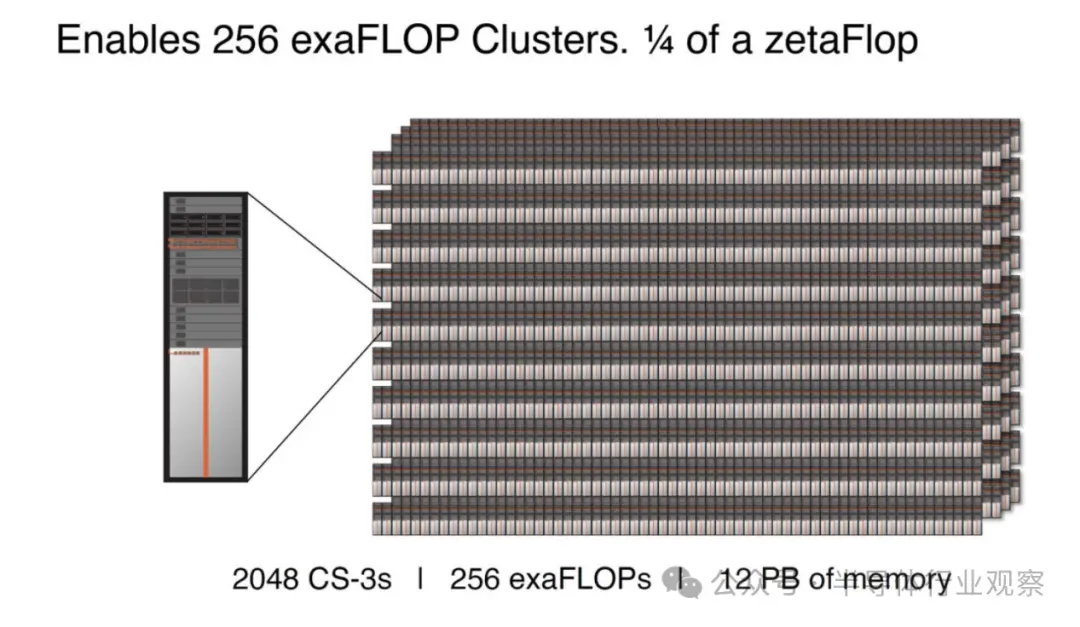
12PB 内存是一款高端超大规模 SKU,专为快速训练 GPT-5 尺寸模型而设计。Cerebras 还可以缩小到类似于单个 CS-2 的规模,并支持服务器和网络。

部分内存不仅是片上内存(44GB),还包括支持服务器中的内存。

因此,Cerebras 集群可以训练比以前更大的模型。
关于整个系统,在SC22的时候,该公司就曾基于 Cerebras CS-2 的系统展示了看起来像一堆金属的东西,其中有一些印刷电路板伸出来。该公司称其为发动机组(Engine Block)。在 Cerebras 看来,这是一项巨大的工程壮举。弄清楚如何封装、供电和冷却大型芯片是一个关键的工程挑战。让代工厂制造特殊的晶圆是一回事,让晶圆开机、不过热并做有用的工作是另一回事。

这是另一边的样子。

当我们谈论由于密度而必须转向液体冷却的服务器时,我们谈论的是 2kW/U 服务器或可能具有 8x800W 或 8x1kW 部件的加速器托盘。对于 WSE/WSE-2,所有电力和冷却都需要传输到单个大晶圆上,这意味着即使是不同材料的热膨胀率等因素也很重要。另一个含义是,实际上该组件上的所有部件都采用液冷方式。

最上面一排木板非常密集。展位上的 Cerebras 代表告诉我,这些是电源,这是有道理的,因为我们看到它们的连接器密度相对较低。

Cerebras Condor Galaxy 的更新
在去年七月,Cerebras 宣布其 CS-2 系统取得重大胜利。它拥有一台价值 1 亿美元的人工智能超级计算机,正在与阿布扎比的 G42 一起使用。这里的关键是,这不仅仅是一个 IT 合作伙伴,也是一个客户。

当前的第一阶段有 32 个 CS-2 和超过 550 个 AMD EPYC 7003“Milan”CPU(注:Cerebras 首席执行官 Andrew Feldman 告诉我他们正在使用 Milan),只是为了向 Cerebras CS-2 提供数据。如今,32 个 GPU 相当于四个 NVIDIA DGX H100 系统,而 32 个 Cerebras CS-2 就像 32 个 NVIDIA DGX H100 集群,每个集群都位于单个芯片上,并在大芯片上进行互连。这更像是数百个(如果不是更多)DGX H100 系统,而这只是第一阶段。

在第二阶段,加利福尼亚州圣克拉拉/科洛沃的安装量预计将在 10 月份增加一倍。

除了Condor Galaxy 1,还有另一个集群,即 Condor Galaxy 2,现已在 G42 上启动并运行。

新的 Condor Galaxy 3 是达拉斯集群,它将使用新的 5nm WSE-3 和 CS-3 进行计算。
据介绍,Condor Galaxy 3将由 64 个 CS-3 系统构建,产生 8 exa FLOP的 AI 计算, 这是世界上最大的 AI 超级计算机之一。Condor Galaxy 3是 Condor Galaxy 网络中的第三个安装。Cerebras G42战略合作伙伴关系旨在提供数十exaFLOPs的人工智能计算能力。Condor Galaxy 训练了一些业界领先的开源模型,包括Jais – 30B、Med42、Crystal-Coder – 7B 和 BTLM- 3B -8K 。

这些是目前位于美国圣克拉拉、斯托克顿和达拉斯的集群,他们计划是再建造至少六个。
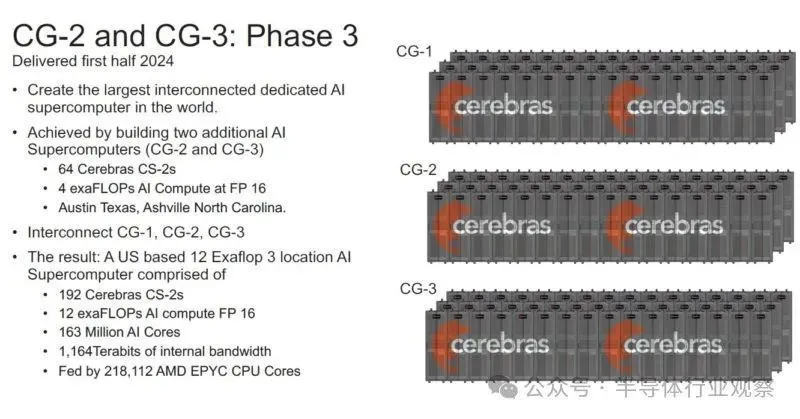
这些集群的总价值应超过 10 亿美元,并于 2024 年完工。除了 10 亿美元的交易价值外,Cerebras 告诉我们,它们目前供应有限,因此对 WSE-3 的需求是存在的。

值得一提的是,虽然 Cerebras 专注于推理训练,但它宣布与高通建立合作伙伴关系,以使用高通的传统人工智能推理加速器。
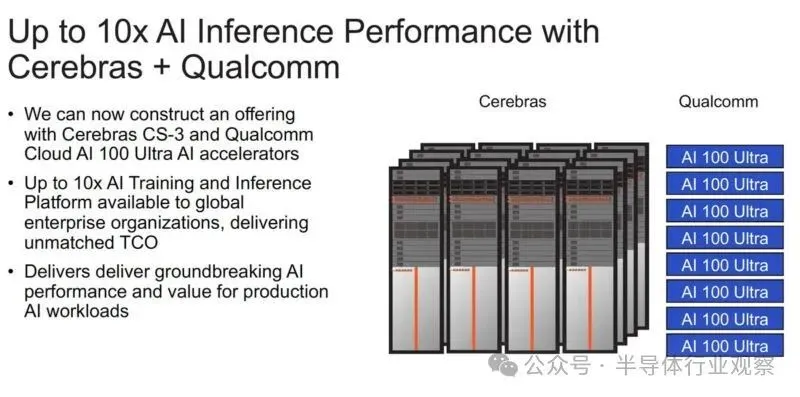
虽然 Cerebras 计算机是为训练而构建的,但 Cerebras 首席执行官安德鲁·费尔德曼 (Andrew Feldman) 表示,推理、神经网络模型的执行才是人工智能采用的真正限制。据 Cerebras 估计,如果地球上每个人都使用ChatGPT,每年将花费 1 万亿美元,更不用说大量的化石燃料能源了。(运营成本与神经网络模型的规模和用户数量成正比。)
因此,Cerebras 和高通建立了合作伙伴关系,目标是将推理成本降低 10 倍。Cerebras 表示,他们的解决方案将涉及应用神经网络技术,例如权重数据压缩和稀疏性(修剪不需要的连接)。该公司表示, 经过 Cerebras 训练的网络将在高通公司的新型推理芯片AI 100 Ultra上高效运行。
写在最后
Cerebras Wafer Scale Engine 系列仍然是一项出色的工程设计。此次发布的一个重要内容是 5nm WSE-3 已经问世。最酷的事情之一是 Cerebras 从流程进步中获得了巨大的进步。
我们知道 AMD MI300X 今年的收入将轻松超过 10 亿美元。Cerebras 预计收入将超过 10 亿美元,假设它正在销售整个集群,而不仅仅是价值数百万美元的 CS-3 盒子。NVIDIA 将于下周在 GTC 上详细讨论 NVIDIA H200 和下一代 NVIDIA B100 时出售 10 亿美元的硬件。我们将收到英特尔 Gaudi3 的最新消息,但我们已经听到一些人分享了 2024 年九位数的销售预测, Cerebras 可能是唯一一家专注于培训、在收入方面与大型芯片制造商竞争的公司。
“八年前, 当我们开始这一旅程时,每个人都说晶圆级处理器是一个白日梦。我们非常自豪能够推出第三代突破性水平的人工智能芯片。”Cerebras 首席执行官兼联合创始人Andrew Feldman)说道。“ WSE-3 是世界上最快的 AI 芯片,专为最新的尖端AI 工作而设计,从专家混合到24 万亿个参数模型 。我们很高兴将 WSE-3 和 CS-3 推向市场,以帮助解决当今最大的人工智能挑战。”
让我们期待Cerebras 2025 年下半年发布WSE-4带来的惊喜。
参考链接
Cerebras Systems Unveils World’s Fastest AI Chip with 4 Trillion Transistors
https://spectrum.ieee.org/cerebras-chip-cs3
https://www.tomshardware.com/tech-industry/artificial-intelligence/cerebras-launches-900000-core-125-petaflops-wafer-scale-processor-for-ai-theoretically-equivalent-to-about-62-nvidia-h100-gpus
评论(0)